Problem Statement:
- Memory samples often provide a poor approximation of the loss landscape of past tasks, especially near a high-loss ridge.
Research Goals:
- Instead of ending up near a high-loss ridge, the method aims to end up on the high-loss ridge.
- Mitigate overfitting to the memory buffer and ensure memory samples approximate the distribution of all past data more effectively.
Proposed Approach:
- Repeated Rehearsal: Perform multiple gradient-update iterations (K) per incoming batch to reduce underfitting. This can be plugged into existing Experience Replay (ER) variants.
- Data Augmentation: Apply random transformations (e.g., RandAugment with parameters P, Q) to both incoming and memory batches at each iteration. This regularizes new data and diversifies the memory distribution.
Adaptive Hyperparameter Tuning:
Use a reinforcement learning agent (bootstrapped policy gradient) to dynamically tune:
- Number of iterations K
- Augmentation strength (P, Q)
- Guided by memory-batch accuracy to detect and respond to overfitting risk
Experimental Setup:
- Datasets: Seq-CIFAR100 (20 tasks), Seq-MiniImageNet (10 tasks), CORE50-NC (9 tasks), CLRS25-NC (5 tasks)
- Memory Sizes: 2,000 and 5,000 samples
- Training Setup: Standard online continual learning configuration
Results:
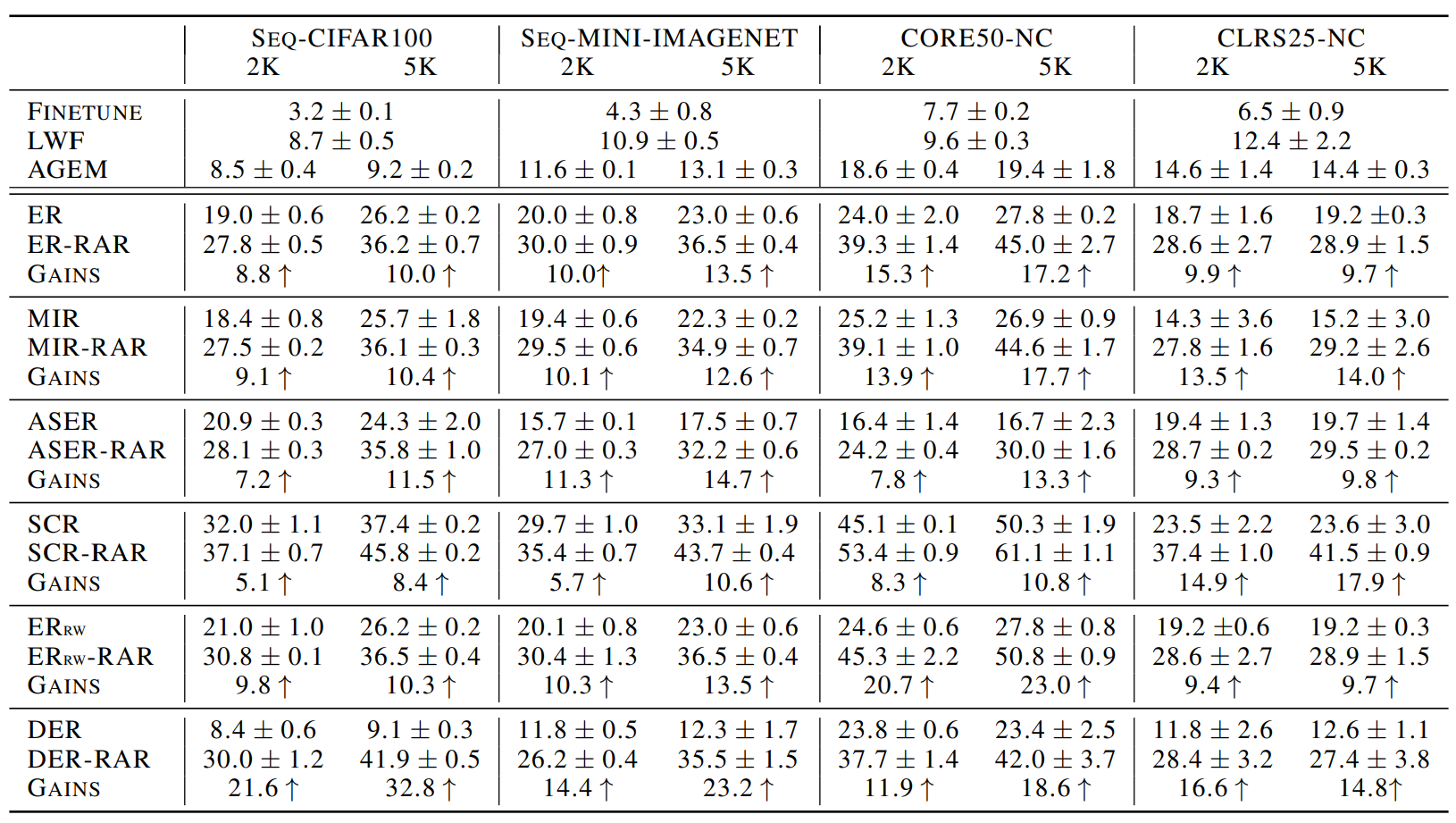
Limitations:
- Hyperparameter tuning depends on external validation data — a limitation also shared by other works like AdaCL.
Strengths:
- A simple yet effective plug-in strategy.
- Improves generalization by diversifying memory and tuning training dynamics adaptively.
Future Work:
- Apply the method beyond image classification, potentially exploring NLP or multimodal tasks.