Authors:
Mark D. McDonnell,
Dong Gong,
Amin Parveneh,
Ehsan Abbasnejad,
Anton van den Hengel
Problem Statement:
- Methods using pre‑extracted features struggle to bridge distribution gaps; adaptor‑based approaches risk forgetting; training-from-scratch CL methods underperform non‑CL baselines and suffer catastrophic forgetting.
Research Goals:
- Bypass catastrophic forgetting via training‑free random projectors and class‑prototype accumulation.
- Demonstrate that decorrelating class prototypes reduces distribution disparity in pre‑trained representations.
Proposed Approach:
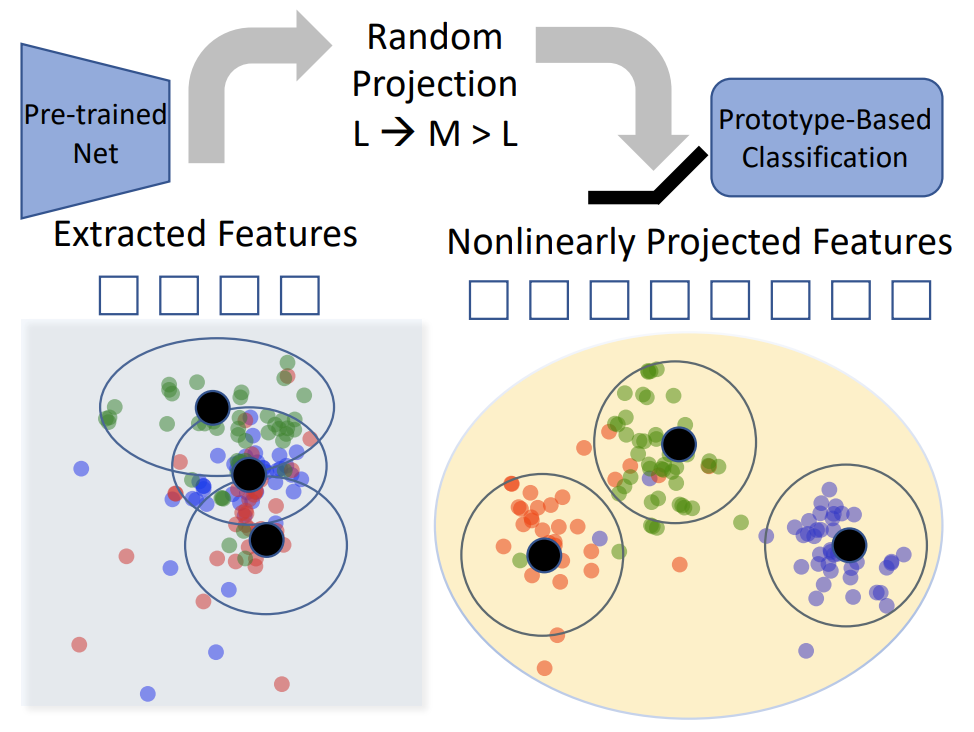
Random‑Projection (RP) Layer
- Inject a frozen, nonlinear random projection layer between the backbone’s feature output and the class‑prototype head.
- Expands feature dimensionality to enhance linear separability; projections are generated once and remain fixed throughout CL.
Class‑Prototype (CP) Accumulation & Classification
- Form class prototypes by averaging feature vectors per class.
- Use incrementally updated second‑order statistics (Gram matrix) to go beyond simple nearest‑mean classification.
Training Setup:
- Phase 1 (optional): PETL methods (AdaptFormer, SSF, VPT) trained on the first stage; head and weights discarded before CL.
- Phase 2: Extract features from frozen pretrained model; update Gram matrix and class prototypes without SGD.
Experimental Setup:
- Datasets: CIFAR‑100, ImageNet‑R, ImageNet‑A, OmniBenchmark, CUB, VTAB, Stanford Cars.
- Hyperparameters: Random projection dims M = 2 000 (also evaluated M = 5 000, 10 000).
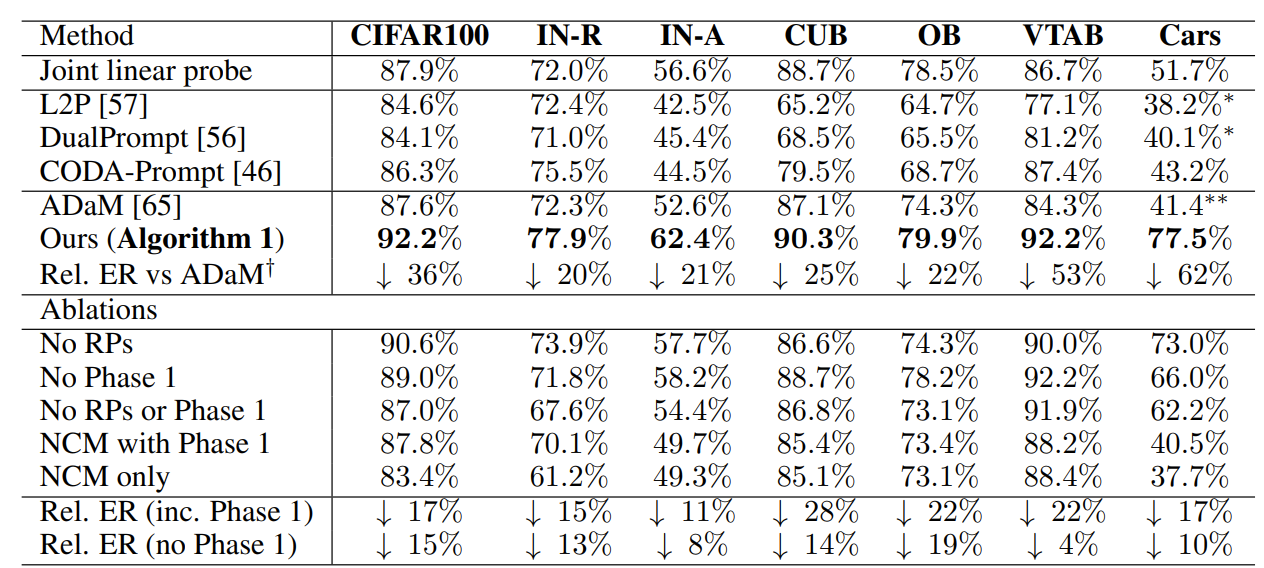
Results:
Limitations:
- Relies entirely on a strong pretrained feature extractor; likely weaker when training from scratch.
Strengths:
- Concise, training‑free approach that effectively prevents forgetting.
- Rehearsal‑free continual learning.
Future Work:
- Explore combining RanPAC with prompting or adapter‑based PETL methods.