Problem Statement:
- Current network expanding models do not mention their storage problem, they do not make a fair comparison with memory methods. This assumption is wrong because storing a model can also be costly. Evaluating the memory and architecture methods under the same consumption conditions may actually yield the same performance.
- They measure that if they exchange model buffer of ResNet32 into exemplars of equal size and append them to ICARL the average accuracy drastically increase from 62 to 70%.
- Resnet32 model (464k parameter size) == 603 images of CIFAR.
Research Goals:
- They make a fair comparison between memory based methods and architecture based methods.
- They propose to changing the assumption of “training a backbone for each task”. Instead they aim to separate general layers from task specific layers and the remaining budget should be spent for keeping the memory.
Proposed Approach:
They analyze the effect of different layers in the backbone and find that sharing the shallow layers and only creating deep layers for new tasks helps save the memory budget in CIL. Furthermore, the spared space can be exchanged for an equal number of exemplars to further boost the performance.
They decompose the model into the embedding module and linear layers. They investigate the models into 3 aspects: Block-wise gradient, shift and similarity of layers. They found that shallow layers tend to stay unchanged during CIL. Hence, they summarize that instead of expanding general layers they say that we should expand specialized layers.
To this end, they expand the specialized layers (e.g last block of Resnet) for each task and optimize the function of:
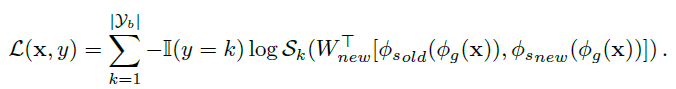
Experimental Setup:
- Dataset: CIFAR100, ImageNet100
- Hyperparameters: There is a lambda hyperparameter that still controls the KD
- Training setup: CIL
Evaluation metrics:
- Incremental ACC, AUC
Results:
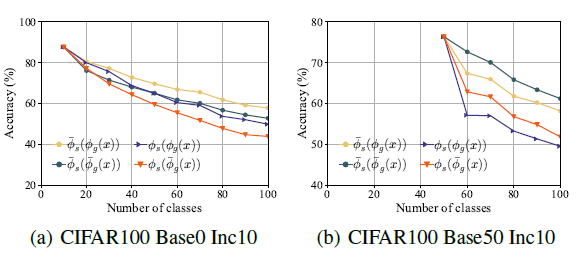
While optimizing the equation they use old backbone as can be seen from the equation as well. In the Figure 1 they find that if they kept the specialized layers of old network fixed and the general layers free, they find better performance. (fi (s) old is kept fixed).
They achieve compatible results with DER.
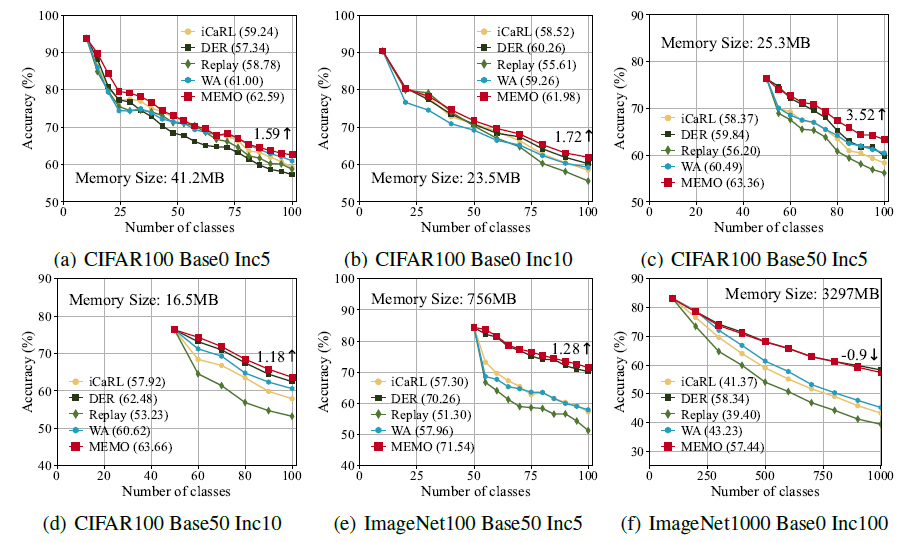
Limitations:
Apart from the methods discussed in this paper, there are other methods that do not save exemplars or models. They only concentrate on the methods with extra memory and select several typical methods for evaluation.
Strengths:
Very well written and fun to read.
Interesting point of research, in the future machines should be able to adjust themselves whether to expand the network.
Future work:
Using the simply last block idea may be investigated further?