Authors:
Qing Sun*,
Fan Lyu*,
Fanhua Shang,
Wei Feng,
Liang Wan†
Problem Statement:
- To understand example influence, one classic technique is the Influence Function (IF), which leverages the chain rule from a test objective to training examples. However, directly applying it leads to high computational complexity.
Research Goals:
- Explore a reasonable influence from each training example to Stability (S) and Plasticity (P), and apply example influence to continual learning training.
- Propose a meta‑learning algorithm, MetaSP, to simulate IF and avoid expensive chain‑rule calculations.
Proposed Approach:
- Hold a pseudo‑update with per‑example perturbations, then use two small validation sets (from old and new data) to compute gradients on those perturbations—these gradients estimate the example’s influence on S and P.
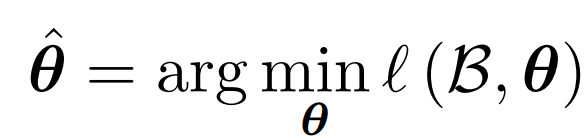
- Fuse S‑ and P‑influences via a Pareto‑optimal mixing weight γ using MGDA, yielding a influence vector I*.
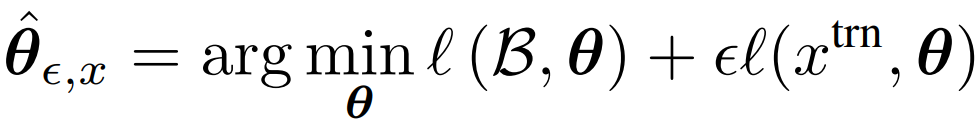
- Use I* to regularize model updates (upweight helpful examples, downweight harmful ones) and to rank examples for rehearsal buffer selection.
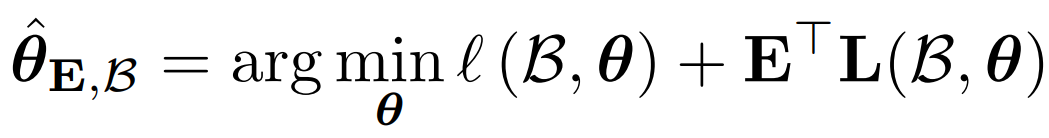
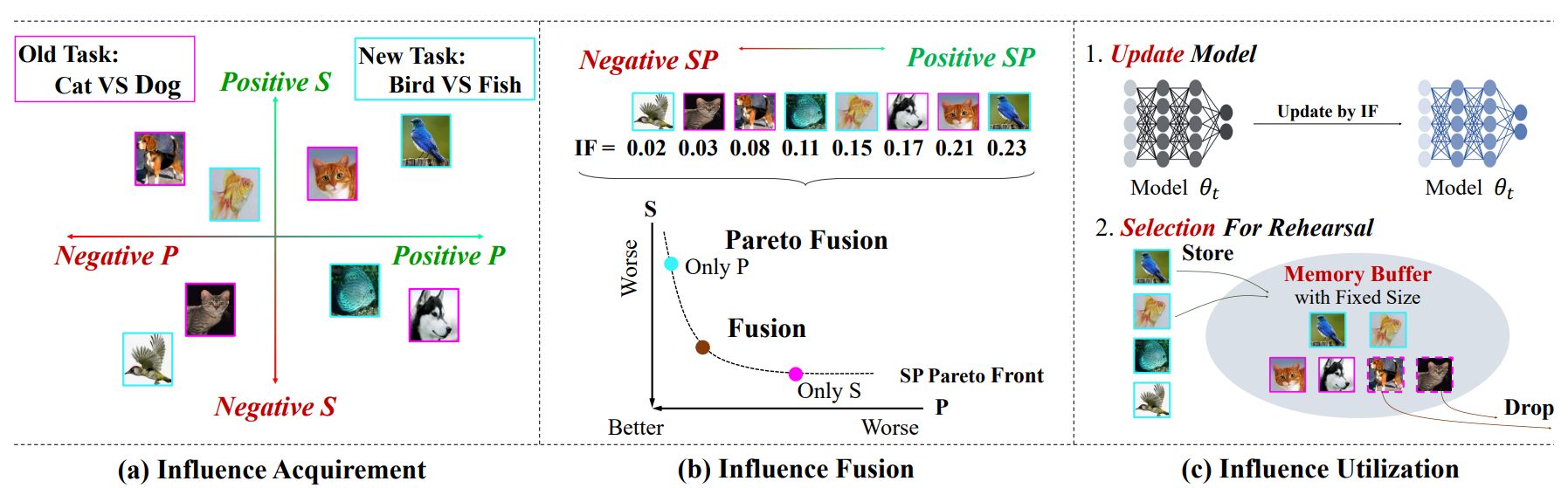
Summarized Steps:
Pseudo‑Update Simulation
- From current parameters θ, perform a one‑step “virtual” update adding small per‑example perturbation E to the batch loss.
Compute S‑ and P‑Aware Influences
- Measure how the pseudo‑update changes losses on two validation sets (Vold and Vnew), and take gradients w.r.t. E.
SP Fusion via Pareto Optimality
- Solve a two‑objective optimization for γ via MGDA to combine S‑ and P‑gradients into I*.
Leveraging Influences
- Model Update: Regularize SGD by subtracting I* >L.
- Rehearsal Selection: Rank examples by I* and store the top ones, dropping the least helpful.
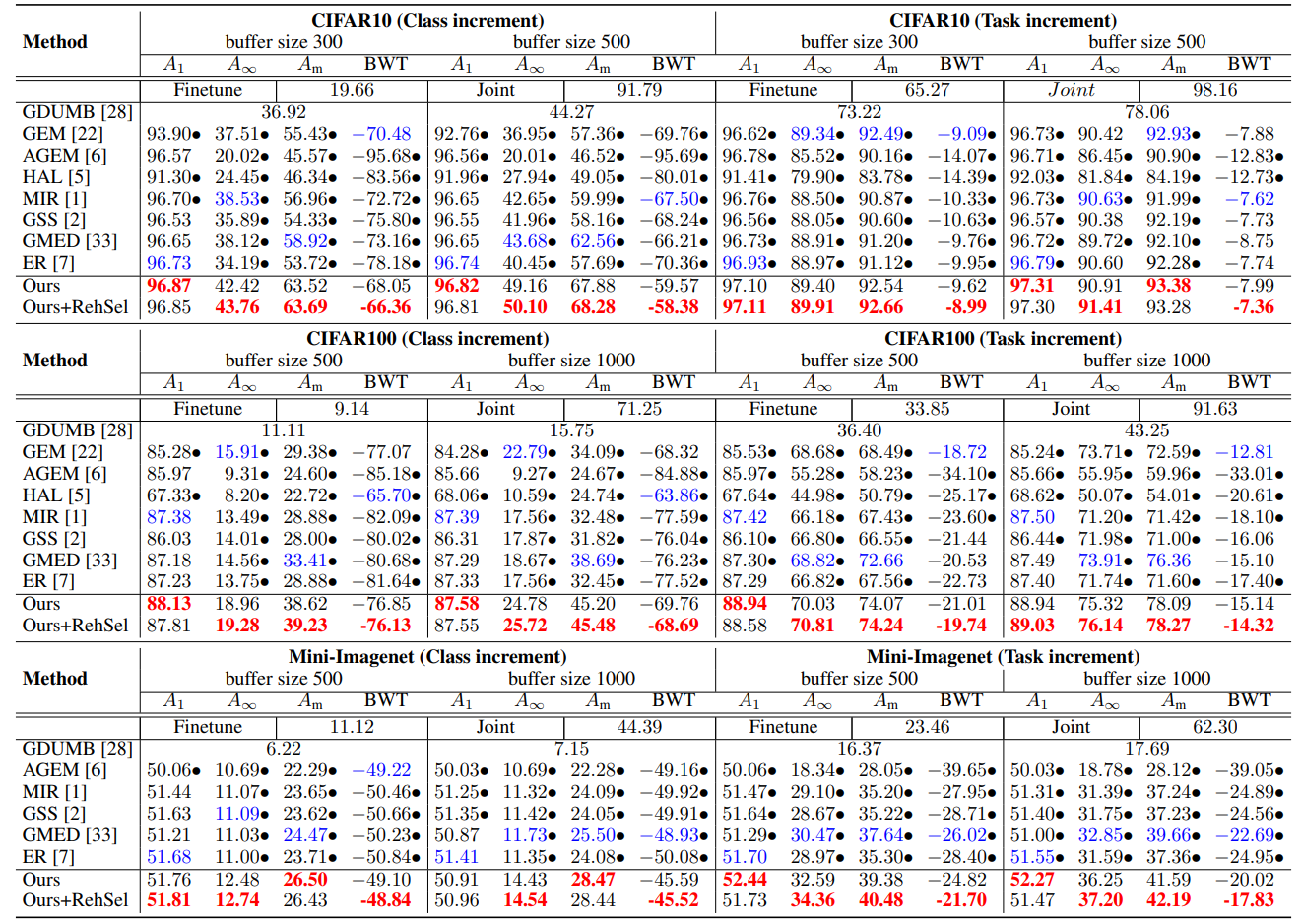
Experimental Setup:
- Benchmarks: Split‑CIFAR‑10, Split‑CIFAR‑100, Split‑Mini‑ImageNet (class‑ and task‑incremental).
- Model: ResNet‑18 from scratch; replay batch size 32; use 10% of buffer & seen data as Vold/Vnew.
- Training: 50 epochs per task; varied replay memory sizes.
Results:
Limitations:
- Relies on a replay buffer, which may not suit privacy‑sensitive or zero‑memory settings.
- Pseudo‑update and dual validation add extra compute overhead.
Strengths:
- Efficiency: Simulates IFs with first‑order gradients—no Hessian inversions—scalable to deep nets.
- Principled Fusion: Uses multi‑objective optimization to balance remembering old tasks and adapting to new ones.
Future Work:
- Explore lighter‑weight validation schemes or proxy metrics to reduce compute overhead.