Problem Statement:
- Mixture of experts are usually trained all at once using whole task data, which makes them all prone to forgetting and increasing computational burden.
Research Goals:
- To address this limitation, they introduce a novel approach named SEED. SEED selects only one, the most optimal expert for a considered task, and uses data from this task to fine-tune only this expert.
Proposed Approach:
The below image very well describes the proposed method:
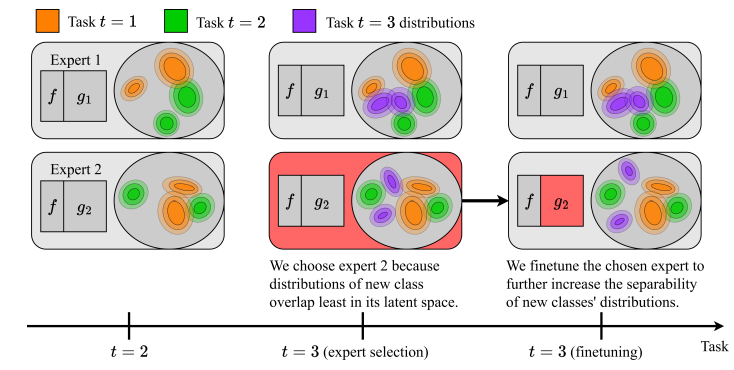
Experimental Setup:
- Dataset: CIFAR100, DomainNet, Imagenetsubset
- Hyperparameters
- Training setup: CIL And the below image describes how they make this CIL
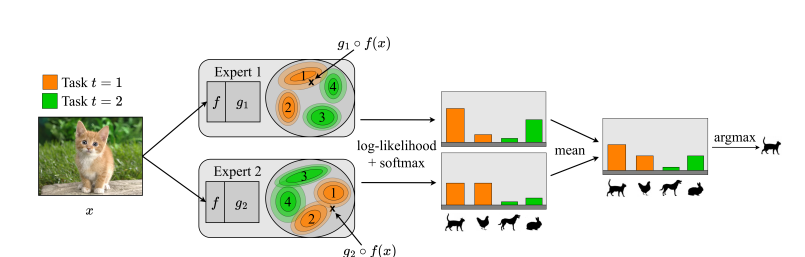
Evaluation metrics:
- Inc Avg Accuracy and Average of Inc Avg Acc.
Results:
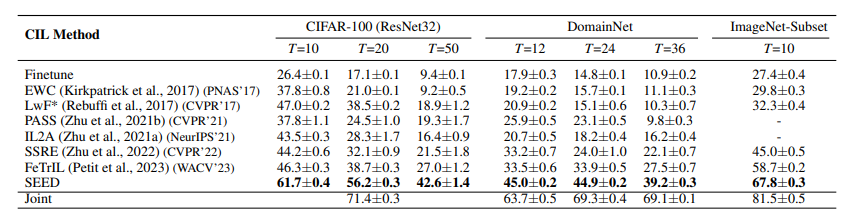
Limitations:
- At some point it will eventually stuck and start to forget.
- I did not understand %100, if we finetune the expert even though with regularization term, how we do not catastrophically forget the previous tasks that are fine-tuned with that Expert.
- Also during test time image is a bit strange. Because let's say the orange Expert is trained with cat and chicken so that's why it classifies it as cat. But then I expect the green Expert to be trained with dog and rabbit and will respond to cat image as dog (because it was the last thing it learned) So I am probably missing something but couldn't figure it out yet what is that.
Strengths:
It is very real life case I think.